
On This Page
Overview
A regular expression is a pattern used to identify text. It allows you to have very fine-grained control over what content DryvIQ detects. The pattern must be constructed according to regular expression standards. There are multiple resources online that explain how to construct a regular expression pattern.
When creating an entity in DryvIQ using regular expression, you can add one to many patterns to ensure the entity type matches exactly what you want to find. You will specify both the pattern and the confidence level for each pattern. You can further improve match accuracy by adding keywords and validation to the entity type.

Entity Type Details
Selecting to edit the Entity type details allows you to enter a description for the entity type you are creating. Separate from the name that will be used to search for the entity type in the application, the description provides your users with an understanding of what the entity type is attempting to accomplish with the rules and validation you select to use. The description is limited to 256 characters.


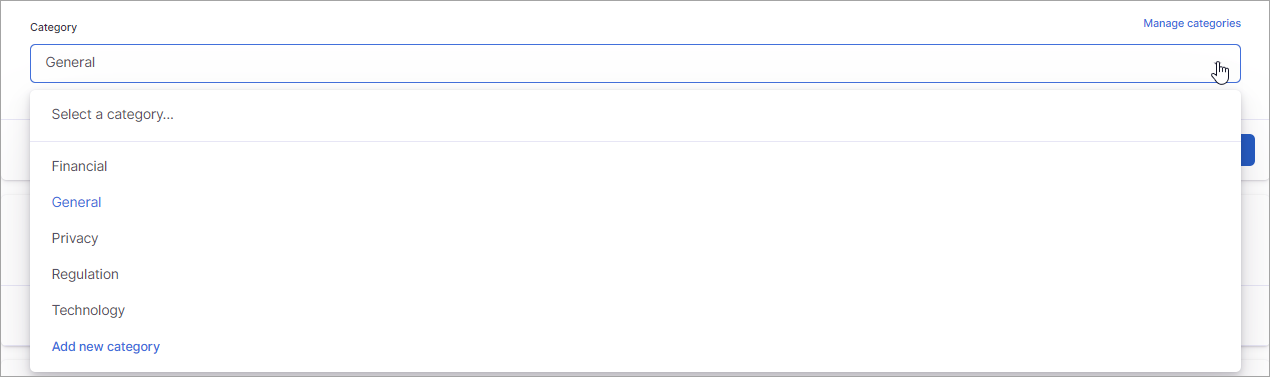
Category
Editing the Entity type details also allows you to edit the category assigned to the entity type. The category identifies the type of data being detected. The Category list includes the five default categories (Financial, General, Privacy, Regulation, and Technology) that come added in the application as well as any custom categories you have created. Preinstalled entity types will be assigned a corresponding category. All custom entity types default to “General,” so you will need to edit the category if a specific category needs to be used for an entity type. (See Managing Categories for information about creating and managing custom categories.)
Regex
This section is where you will build your regular expression pattern and assign a confidence level.
Description
The Description is a user-defined name for the pattern you are going to use. This helps identify the pattern. While this is an optional field for the regular expression patterns you add, DryvIQ recommends adding a description since this makes it easier for other users to understand the pattern when reviewing the information.

Regex Pattern
The Regex pattern is the regular expression pattern you want to use for the entity type. Again, the pattern must be constructed according to regular expression standards.

The timeout for matching regex patterns is 5 minutes per pattern in an entity type. If a match takes longer than the timeout, an error will be logged in the Activity report for the policy indicating the regex engine timed out.
Confidence
The confidence level provides a simple mechanism for you to control how many false positives you are willing to tolerate. The Confidence list displays the available levels. Each confidence level maps to a threshold (or probability in machine learning-based models) that is used throughout the rest of entity type model.
The confidence level mapping is as follows:
None= 0
Very weak = 0.05
Weak = 0.3
Medium = 0.5
Strong = 0.7
Very strong = 0.85

Select Add regex pattern to add additional patterns. You can add as many patterns to the entity type as you like to help strengthen the match.
Validations
Like keyword, validations are a way to improve the match success. DryvIQ comes will preinstalled validation rules that can validate social security numbers, checksums, driver license numbers, and so on. You can choose validation rules from the list, and DryvIQ will run all the matches against the selected validation rules. Any match that fails validation will automatically be filtered out of the result list. For example, if you set a credit card pattern to detect credit card numbers, you should also select to apply the Luhn Check validation to ensure the matches are valid credit card numbers. This extra validation limits the number of false positive matches that you will need to sort through. Again, adding validations increases the match success by the percentage identified.

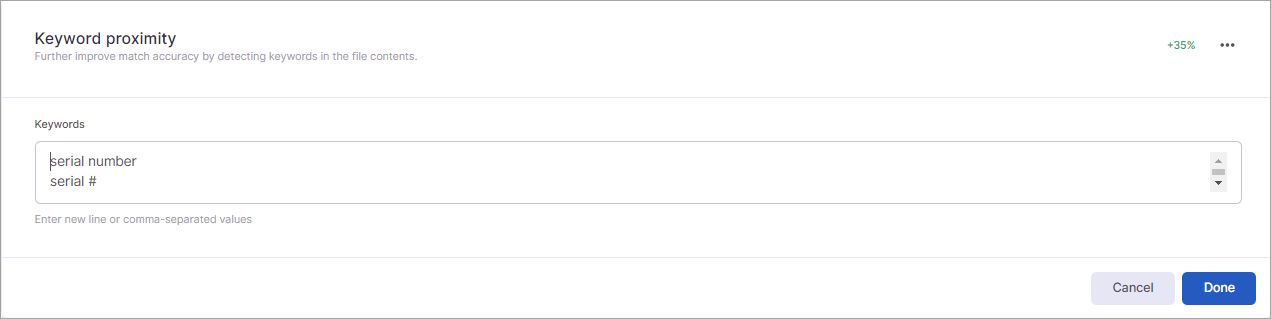
Keyword Proximity
You can further improve the match accuracy by providing a list of keywords that may appear in close proximity to the entity you want to identify. A term is considered as close proximity if it within 5 words behind the match by default. These keywords boost the confidence level of a given match. In the example, the confidence level for the serial number pattern used in the example may only be 0.5 (medium); however, if you add keywords, the confidence level increases by 35% (as noted by the green percentage displayed on the right of this section).
Keywords
Keywords can be manually added to the Keywords field orimported using a CSV file. When manually adding keywords, you can enter the terms as a comma-separated values, or you can add each keyword on a new line.

See Managing Keywords for information about managing keywords added to the entity type.
Maximum Distance From Match
These fields allow you to set a custom keyword proximity. By default, a term within 5 words before the regular expression pattern will trigger a match confidence adjustment. You can edit the field to specify the distance you prefer to use. You can also turn on proximity to search for keywords after the regular expression pattern and specify the value you want to use.

Clearing the checkbox for the words before or words after proximity field disables the proximity search in that direction. You should not disable both fields since doing so turns keyword matching off.
Negative Keyword Proximity
The Negative keyword list is an explicit list of words or phrases that should prevent a match if detected within proximity of the regular expression pattern, which assists in reducing false positives. For an upload against an entity type, the match confidence will be 0% if a negative keyword is found. For a policy, the presence of a negative keyword, even if other validation and keywords are present, will prevent the item from being matched and assigned to the corresponding tracking group.
Negative Keywords
Negative keywords can be manually added to the Negative keywords field or imported using a CSV file. When manually adding keywords, you can enter the terms as a comma-separated values, or you can add each keyword on a new line.
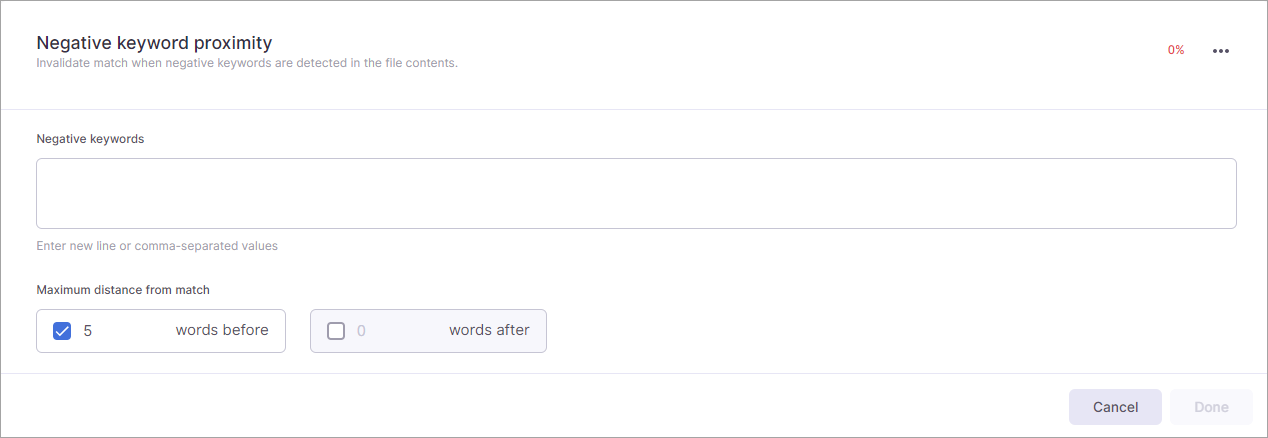
Maximum Distance From Match
These fields allow you to set a custom keyword proximity. By default, a term within 5 words before the regular expression pattern will trigger a match confidence adjustment. You can edit the field to specify the distance you prefer to use. You can also turn on proximity to search for keywords after the regular expression pattern and specify the value you want to use. Clearing the checkbox for the words before or words after proximity field disables the proximity search in that direction. You should not disable both fields since doing so turns keyword matching off.